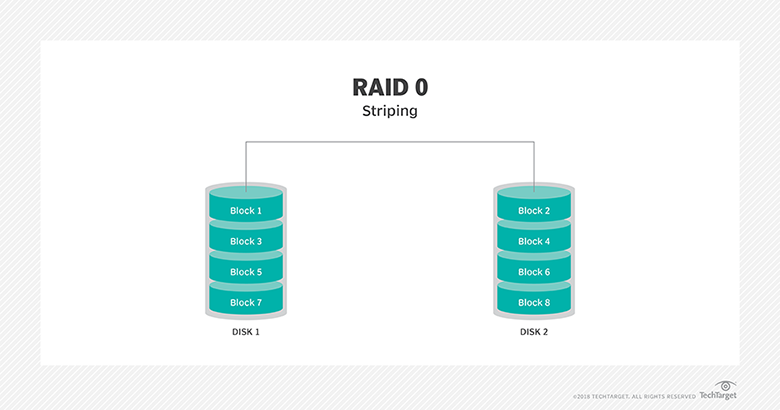
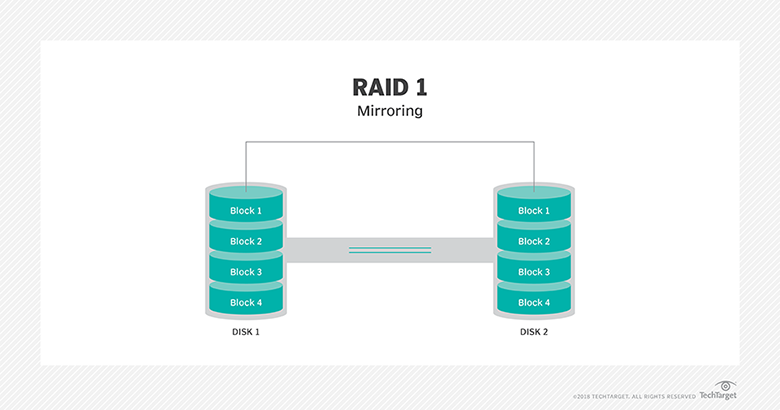
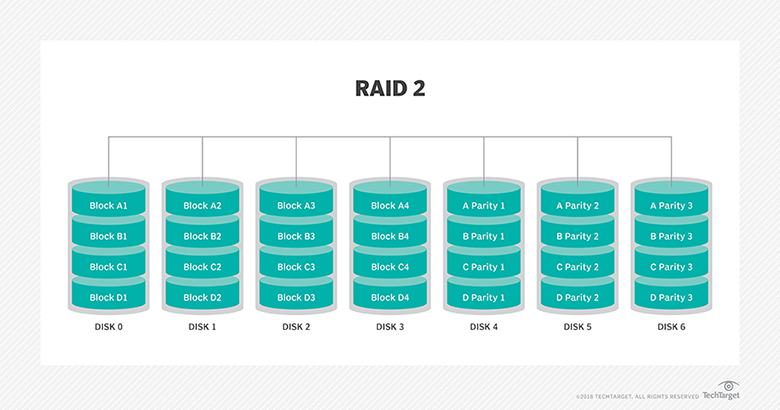
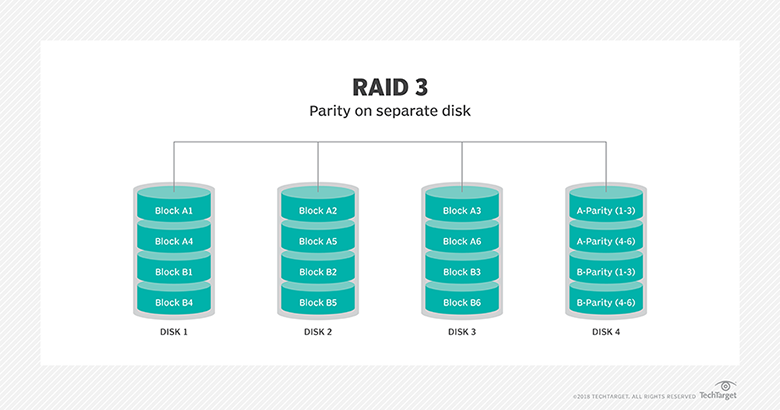
Describe the difference between all the storage access technologies
Difference between SAN AND NAS; block and file
A storage area network (SAN) is storage connected in a fabric (usually through a switch) so that there can be easy access to storage from many different servers. From the server application and operating system standpoint, there is no visible difference in the access of data for storage in a SAN or storage that is directly connected. A SAN supports block access to data just like directly attached storage.
Network-attached storage (NAS) is really remote file serving. Rather than using the software on your own file system, the file access is redirected using a remote protocol such as CIFS or NFS to another device (which is operating as a server of some type with its own file system) to do the file I/O on your behalf. This enables file sharing and centralization of management for data.
So from a system standpoint, the difference between SAN and NAS is that SAN is for block I/O and NAS is for file I/O. One additional thing to remember when comparing SAN vs. NAS is that NAS does eventually turn the file I/O request into a block access for the storage devices attached to it.
Block level storage
Anyone who has used a Storage Area Network (SAN) has probably used block level storage before. Block level storage presents itself to servers using industry standard Fibre Channel and iSCSI connectivity mechanisms. In its most basic form, think of block level storage as a hard drive in a server except the hard drive happens to be installed in a remote chassis and is accessible using Fibre Channel or iSCSI.
When it comes to flexibility and versatility, you can’t beat block level storage. In a block level storage device, raw storage volumes are created, and then the server-based operating system connects to these volumes and uses them as individual hard drives. This makes block level storage usable for almost any kind of application, including file storage, database storage, virtual machine file system (VMFS) volumes, and more. You can place any kind of file system on block level storage. So, if you’re running Windows, your volumes will be formatted with NTFS; VMware servers will use VMFS.
File level storage devices are often used to share files with users. By creating a block-based volume and then installing an operating system and attaching to that volume, you can share files out using that native operating system. Remember, when you use a block-based volume, you’re basically using a blank hard drive with which you can do anything.
When it comes to backup, many storage devices include replication-type capabilities, but you still need to think about how to protect your workloads. With this type of storage, it’s not unusual for an organization to be able to use operating system native backup tools or third-party backup tools such as Data Protection Manager (DPM) to back up files. Since the storage looks and acts like a normal hard drive, special backup steps don’t need to be taken.
With regard to management complexity, block-based storage devices tend to be more complex than their file-based counterparts; this is the tradeoff you get for the added flexibility. Block storage device administrators must:
- Carefully manage and dole out storage on a per server basis.
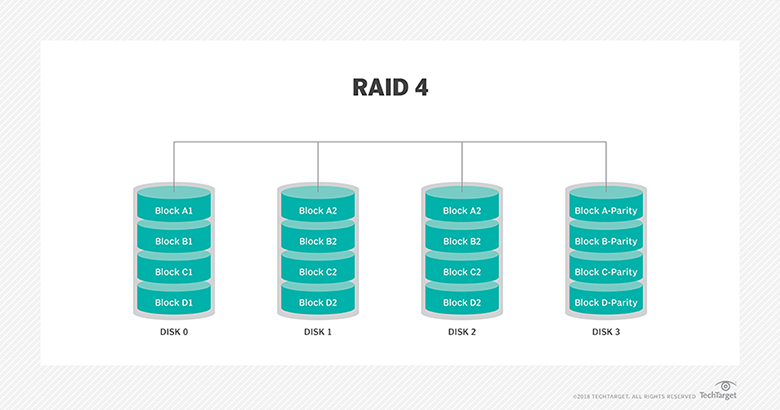
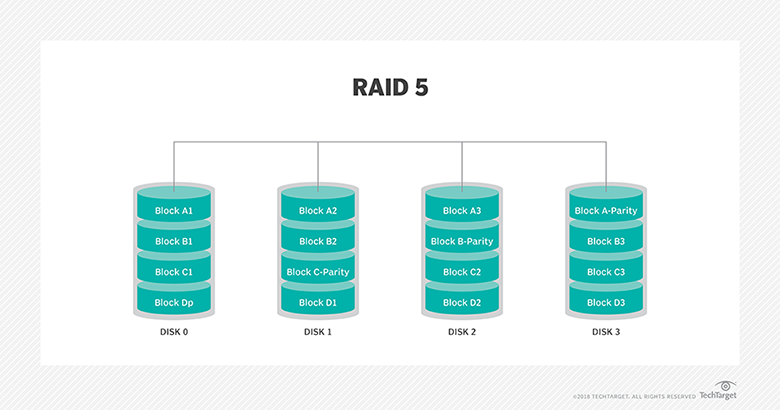
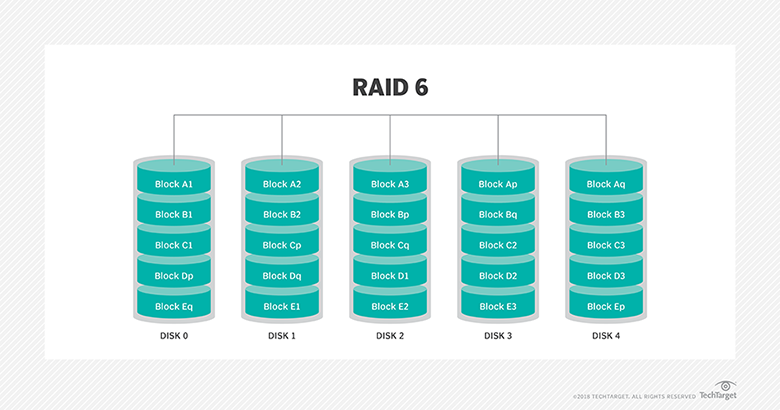
- Manage storage protection levels (i.e., RAID).
- Track storage device performance to ensure that performance continues to meet server and application needs.
- Manage and monitor the storage communications infrastructure (generally iSCSI or Fibre Channel).
From a use case standpoint, there are a lot of applications that make use of this block-level shared storage, including:
- Databases. This is especially true when you want to cluster databases, since clustered databases need shared storage.
- Exchange. Although Microsoft has made massive improvements to Exchange, the company still does not support file level or network-based (as in, CIFS or NFS) storage. Only block level storage is supported.
- VMware. Although VMware can use file level storage via Network File System (NFS), it’s very common to deploy VMware servers that use shared VMFS volumes on block level storage.
- Server boot. With the right kind of storage device, servers can be configured to boot from block level storage.
File level storage
Although block level storage is extremely flexible, nothing beats the simplicity of file level storage when all that’s needed is a place to dump raw files. After all, simply having a centralized, highly available, and accessible place to store files and folders remains the most critical need in many organizations. These file level devices — usually Network Attached Storage (NAS) devices — provide a lot of space at what is generally a lower cost than block level storage.
File level storage is usually accessible using common file level protocols such as SMB/CIFS (Windows) and NFS (Linux, VMware). In the block level world, you need to create a volume, deploy an OS, and then attach to the created volume; in the file level world, the storage device handles the files and folders on the device. This also means that, in many cases, the file level storage device or NAS needs to handle user access control and permissions assignment. Some devices will integrate into existing authentication and security systems.
On the backup front, file level storage devices sometimes require special handling since they might run non-standard operating systems, so keep that in mind if you decide to go the file level route.
With the caveat that you may need to take some steps with regard to authentication, permissions, and backup, file level-only devices are usually easier to set up than block level devices. In many cases, the process can be as simple as walking through a short configuration tool and moving forward.
If you’re looking for storage that screams — that is, if you need high levels of storage performance — be very careful with the file level option. In most cases, if you need high levels of performance, you should look at the block level options. Block level devices are generally configurable for capacity and performance. Although file-level devices do have a performance component, capacity is usually the bigger consideration.
File level use cases are generally:
- Mass file storage. When your users simply need a place to store files, file-level devices can make a lot of sense.
- VMware (think NFS). VMware hosts can connect to storage presented via NFS in addition to using block level storage.
Block technologies
Fibre Channel
Fibre Channel is a technology for transmitting data between computer devices at data rates of up to 16 Gbps. Fibre Channel is especially suited for connecting computer servers to shared storage devices and for interconnecting storage controllers and drives. Since Fibre Channel is three times as fast, it has begun to replace the Small Computer System Interface (SCSI) as the transmission interface between servers and clustered storage devices. Fibre channel is more flexible; devices can be as far as ten kilometers (about six miles) apart if optical fiber is used as the physical medium. Optical fiber is not required for shorter distances, however, because Fibre Channel also works using coaxial cable and ordinary telephone twisted pair.
Fibre Channel offers point-to-point, switched, and loop interfaces. It is designed to interoperate with SCSI, the Internet Protocol (IP) and other protocols, but has been criticized for its lack of compatibility – primarily because (like in the early days of SCSI technology) manufacturers sometimes interpret specifications differently and vary their implementations.
The world wide name (WWN) in the switch is equivalent to the Ethernet MAC address. As with the MAC address, you must uniquely associate the WWN to a single device. The principal switch selection and the allocation of domain IDs rely on the WWN. The WWN manager, a process-level manager residing on the switch’s supervisor module, assigns WWNs to each switch.
FC addresses are FCIDs, which get assigned by a switch, based on its internal representation of its ports. Each node is identified by an 8-bit Port_ID.
iSCSI
iSCSI is a transport layer protocol that describes how Small Computer System Interface (SCSI) packets should be transported over a TCP/IP network.
iSCSI, which stands for Internet Small Computer System Interface, works on top of the Transport Control Protocol (TCP) and allows the SCSI command to be sent end-to-end over local-area networks (LANs), wide-area networks (WANs) or the Internet. IBM developed iSCSI as a proof of concept in 1998, and presented the first draft of the iSCSI standard to the Internet Engineering Task Force (IETF) in 2000. The protocol was ratified in 2003.
iSCSI works by transporting block-level data between an iSCSI initiator on a server and an iSCSI target on a storage device. The iSCSI protocol encapsulates SCSI commands and assembles the data in packets for the TCP/IP layer. Packets are sent over the network using a point-to-point connection. Upon arrival, the iSCSI protocol disassembles the packets, separating the SCSI commands so the operating system (OS) will see the storage as a local SCSI device that can be formatted as usual. Today, some of iSCSI’s popularity in small to midsize businesses (SMBs) has to do with the way server virtualization makes use of storage pools. In a virtualized environment, the storage pool is accessible to all the hosts within the cluster and the cluster nodes nodes communicate with the storage pool over the network through the use of the iSCSI protocol.
FCoE
FCoE (Fibre Channel over Ethernet) is a storage protocol that enable Fibre Channel communications to run directly over Ethernet. FCoE makes it possible to move Fibre Channel traffic across existing high-speed Ethernet infrastructure and converges storage and IP protocols onto a single cable transport and interface.
The goal of FCoE is to consolidate input/output (I/O) and reduce switch complexity as well as to cut back on cable and interface card counts. Adoption of FCoE been slow, however, due to a scarcity of end-to-end FCoE devices and a reluctance on the part of many organizations to change the way they implement and manage their networks.
Traditionally, organizations have used Ethernet for TCP/IP networks and Fibre Channel for storage networks. Fibre Channel supports high-speed data connections between computing devices that interconnect servers with shared storage devices and between storage controllers and drives. FCoE shares Fibre Channel and Ethernet traffic on the same physical cable or lets organizations separate Fibre Channel and Ethernet traffic on the same hardware.
FCoE uses a lossless Ethernet fabric and its own frame format. It retains Fibre Channel’s device communications but substitutes high-speed Ethernet links for Fibre Channel links between devices.
FCIP
Fibre Channel over IP (FCIP or FC/IP, also known as Fibre Channel tunneling or storage tunneling) is an Internet Protocol (IP)-based storage networking technology developed by the Internet Engineering Task Force (IETF). FCIP mechanisms enable the transmission of Fibre Channel (FC) information by tunneling data between storage area network (SAN) facilities over IP networks; this capacity facilitates data sharing over a geographically distributed enterprise. One of two main approaches to storage data transmission over IP networks, FCIP is among the key technologies expected to help bring about rapid development of the storage area network market by increasing the capabilities and performance of storage data transmission.
File Technologies
CIFS
The Common Internet File System (CIFS) is a protocol that gained rapid popularity around the turn of the millennium (the year 2000) as vendors worked to establish an Internet Protocol-based file-sharing protocol. At its peak, CIFS was widely supported by operating systems (OSes) such as Windows, Linux and Unix.
CIFS uses the client/server programming model. A client program makes a request of a server program (usually in another computer) to access a file or to pass a message to a program that runs in the server computer. The server takes the requested action and returns a response.
CIFS is a public or open variation of the original Server Message Block (SMB) protocol developed and used by Microsoft. Like the SMB protocol, CIFS runs at a higher level and uses the Internet’s TCP/IP protocol. CIFS was viewed as a complement to existing Internet application protocols such as the File Transfer Protocol (FTP) and the Hypertext Transfer Protocol (HTTP). Today, CIFS is widely regarded as an obsolete protocol. Although some OSes still support CIFS, newer versions of the SMB protocol — such as SMB 2.0 and SMB 3.0 — have largely taken the place of CIFS.
Some capabilities of the CIFS protocol include:
- The ability to access files that are local to the server and read and write to them;
- File sharing with other clients using special locks;
- Automatic restoration of connections in case of network failure
- Unicode file names.
NFS
The Network File System (NFS) is a client/server application that lets a computer user view and optionally store and update file on a remote computer as though they were on the user’s own computer. The user’s system needs to have an NFS client and the other computer needs the NFS server. Both of them require that you also have TCP/IP installed since the NFS server and client use TCP/IP as the program that sends the files and updates back and forth. (However, the User Datagram Protocol, UDP, which comes with TCP/IP, is used instead of TCP with earlier versions of NFS.)
NFS was developed by Sun Microsystems and has been designated a file server standard. Its protocol uses the Remote Procedure Call (RPC) method of communication between computers.
Using NFS, the user or a system administrator can mount all or a portion of a file system (which is a portion of the hierarchical tree in any file directory and subdirectory, including the one you find on your PC or Mac). The portion of your file system that is mounted (designated as accessible) can be accessed with whatever privileges go with your access to each file (read-only or read-write).
Stay tuned for our next blog posts we will learning about basic SAN storage concepts and please subscribe to our YouTube channel named "youngccnaguru lab".